Mit Data Streaming einen Schritt schneller!

Unternehmen haben heutzutage verschiedenste Möglichkeiten Daten zu sammeln und diese in ihrer Marketingkommunikation zu nutzen. Hierbei spielt die Schnelligkeit der Datenverarbeitung eine große Rolle. Data Streaming, also die Echtzeitverarbeitung der Datenquellen, schafft für Unternehmen einen Wettbewerbsvorteil und kurze Reaktionszeiten. In diesem Blogbeitrag erfahren Sie von unserem Gastautor Jannik Franz, Consultant bei DYMATRIX, was Data Streaming ist, welche Technologien dahinter stecken und welche Vorteile es bringt.
Was ist Data Streaming?
Data Streaming oder auch Stream Processing ist ein Prozess, der aus Datenquellen einen kontinuierlichen Datenstrom generiert. In der Regel werden die Daten in Real-Time in kleinen Paketen übermittelt. Erzeugt werden diese Daten bei der Nutzung von bspw. Mobil- oder Webapplikationen, E-Commerce-Einkäufen oder beim Besuch am Point of Sale in der Filiale. Im Big Data Umfeld wird Data Streaming immer wichtiger.
Data Processing ist technisch gesehen ein kontinuierlicher, inkrementeller Datenfluss. Dabei werden die zu verarbeitenden Daten in kleineren Paketen, die so genannte Micro-Batches übermittelt. Dies kann entweder über einen definierten Zeitraum (z.B. jede Sekunde), die Datenmenge (z.B. alle 100 eingehenden Events) oder anhand der Daten selbst (z.B. eine Websession) passieren. So können Streaming-Daten zur Auswertung des Onlineverhaltens der Kunden genutzt werden, um individuellere Angebote innerhalb einer User Journey in Real-Time zu generieren.
Data Streaming lässt sich in zwei Arten von Streams unterteilen:
- Push
- Pull
Bei einem Push Stream schreibt eine Software die Micro-Batches in einen Dienst, der diese bei Eintreffen verarbeitet. Dies eignet sich besonders für Datenquellen, die sich inhärent schon als Stream eignen, also Software oder Lösungen, die konstant Daten generieren. Beispiele sind Sensoren im Auto, Bild und Ton von Kameras oder Logs von Überwachungsdiensten.

Ein Pull Stream hingegen ruft in stetigen Abständen die Micro-Batches selbstständig aus einem Dienst ab. So kann bspw. eine Webschnittstelle, die Daten bereitstellt, in einen Stream umfunktioniert werden. Web- oder Apptrackingdaten werden von Dienstleistern häufig über solche Webschnittstellen bereitgestellt. Bei Pull Streams ist zu beachten, dass die Daten nicht schneller verarbeitet werden können, als sie erzeugt werden. Wenn also Daten nur jede Minute der Webschnittstelle zur Verfügung gestellt werden, bringt auch ein sekündliches Abrufen keinen Mehrwert.
Streaming Technologie
Mittlerweile sind sehr viele verschiedene Streaming Technologien im Umlauf. Die stärksten offenen Vertreter sind Apache Kafka, Apache Spark Streaming sowie Apache Storm. Als reinen Clouddienst stellt Amazon seinen Streamingdienst Kinesis in der AWS zur Verfügung.
Apache SparkTM Streaming baut auf der Implementierung von Spark auf und steht daher in Scala, Java sowie Python zur Verfügung. Da sich Spark für Lade- und Analytik-Prozesse bereits großer Beliebtheit erfreut, fällt es Anwendern hier besonders leicht ihre bestehenden Auswertungen in einen Stream zu integrieren.
Amazon Kinesis bietet Entwicklungswerkzeuge für die gängigsten Programmiersprachen, u. A. Java, .NET oder Python. So können mit geringem Aufwand ganze Anwendungen aufgebaut werden, die Streams beliefern oder abrufen.
Vorteile von Data Streaming
Wenn vor allem Wert darauf gelegt wird einzelne Ereignisse sehr zeitnah zu verarbeiten, schlägt Stream Processing die Batch Verarbeitung. So können auf Ereignisse in den Geschäftsprozessen schnell reagiert werden, bspw. dem Kunden das richtige Produktangebot in diesem bestimmten Moment anzuzeigen. Auch Machine Learning Modelle kommen heute im Data Streaming zum Einsatz, um Vorhersagen zu bestimmten Situationen in Echtzeit zu treffen.
Ein weiterer Einsatz von Data Streaming ist die kontinuierliche Verarbeitung in einem ETL-Prozess von Daten aus Quellsystemen. So kann ein bestehender ETL-Prozess in Spark relativ einfach in einen Streamingjob umgewandelt werden. Durchgehend fallen wichtige Daten auf Webseiten, Apps oder an Kassensystemen in der Filiale an. Mit einem Streaming ETL kann sofort reagiert und wichtige Informationen der digitalen sowie analogen Customer Journey hinzugefügt werden, während bei einem klassischen ETL nur am darauffolgenden Tag reagiert werden kann.
Neuen Usern kann so bspw. ein anderes Sortiment und individuelle Angebote auf einer E-Commerce Webseite präsentiert werden, wenn ihr Verhalten auf bestimmte Profile schließen lässt. Oder ihnen kann individuelle Unterstützung angeboten werden.
Unterschiede Stream Processing zu Batch Verarbeitung
Streaming verändert die Art und Weise, wie ETL-Prozesse aufgebaut werden. Bei der klassischen Batch Verarbeitung werden alle Daten in einem Abwasch (eben Batch) verarbeitet. Diese Berechnungen und Datenschiebungen dauern in der Regel sehr lange. Bei Streaming ist die Erwartungshaltung, dass Daten innerhalb von Millisekunden weiterverarbeitet werden. Da auf sehr kleinen Datenmengen gearbeitet wird, ist dies oft kein Problem. Schwieriger wird es, sobald eine performante Anreicherung mit Informationen aus weiteren Quellen, zum Beispiel dem Data Warehouse wie bei der Batch Verarbeitung, nötig wird. Eine weitere Herausforderung ist, dass die komplette Datenpipeline auf Streaming ausgelegt sein muss. Die Fähigkeit der schnellen Verarbeitung wird sozusagen auch eine Pflicht der schnellen Verarbeitung. Wenn einzelne Teile zu langsam arbeiten oder blockiert sind, bricht der Hauptvorteil von Streams weg.
Zudem muss beachtet werden, dass in den Einzelschritten auf kleinen Mengen gearbeitet wird. Das bedeutet, dass diese weiterverarbeitet, angereichert oder mit vorberechneten Modellen kombiniert werden können, aber keine ganzheitlichen Aggregationen oder Modelle aufgebaut werden können.
Die Berücksichtigung dieser Kriterien ergibt den großen Vorteil, dass die relevanten Daten dort ankommen, wo sie benötigt werden und zwar dann, wann sie anfallen.
| Stream Processing | Batch Verarbeitung | |
|---|---|---|
| Verarbeitungsvolumen | Verarbeitung der Daten aus einem gleitenden Zeitfenster oder der neusten Datensätzen | Verarbeitung der Daten über die gesamte oder einen großen Teil der Datenbasis |
| Abzugsvolumen | Micro-Batches mit geringen Datenaufzeichnungen | Große Mengen angesammelter Daten |
| Performance | Verzögerungen von Sekunden oder geringer erforderlich | Berechnungen und Übertragungen im Minuten bis Stundentakt |
| Auswertungspotential | Reaktionen auf individuelle Ereignisse, Aggregate und gleitende Messungen | Komplexe Analysen über gesamte Datenbasis |
Streaming Architektur
Wie bereits erwähnt, helfen Streams vor allem, um eine beschleunigte Verarbeitung von Einzelevents zu gewährleisten. Allerdings kann damit nicht den Aufbau von Modellen oder das Bauen von Reports über große Zeiträume gehandhabt werden. Deshalb wird sich oft für eine hybride Architektur, die sogenannte Lambda-Architektur, entschieden, um das Beste aus beiden Welten zu kombinieren.
Bei der Lambda-Architektur wird die Verarbeitung in zwei Ebenen aufgeteilt: Die Speed-Layer und die Batch-Layer. In der Batchebene werden wie gewohnt Daten in großen Mengen vorgehalten und batchweise verarbeitet. In der Speed Ebene wird ein Stream aufgebaut, der in kleinen Chunks die Daten direkt auswertet und an ihren Bestimmungsort schreibt.
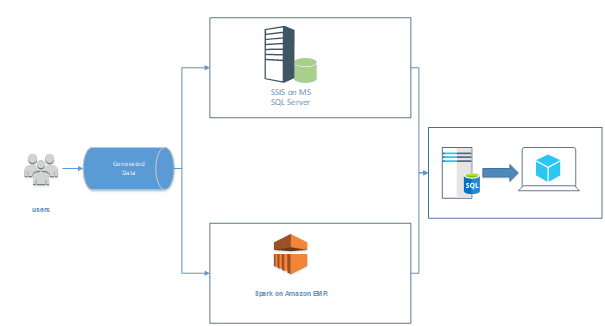
In „Abbildung 2: Lambda-Architektur“ wird eine solche Architektur dargestellt. Zum einen werden die generierten Daten eines Tages mit SSIS abgeholt und in den SQL Server geschrieben (Batch-Layer). Zum anderen erzeugt Spark einen Stream zur Schnittstelle der generierten Daten und ruft diese in einer erhöhten Frequenz ab, um diese der Anwendung (bspw. über dedizierte, kleinere Tabellen im SQL Server) bereitzustellen.
Zusammenfassung
Abschließend bleibt zu sagen, dass Stream Processing nicht die Allheillösung für Datenmanagement ist, jedoch als weiteres, äußerst flexibles Tool im Werkzeugkasten die Möglichkeiten in Lade- und Analytik-Strecken stark erweitern wird. Vor allem Scorings auf vortrainierte Modelle können gut in Streams integriert und direkt ausgespielt werden. Auch direkte Reaktionen auf Ereignisse sind ein großes Plus von Streams.
Ob die Implementation eines Streams als zusätzliche Pipeline oder gar als Ersatz für bestehende Ladeprozesse sinnvoll ist, ist jedoch immer vom jeweiligen Anwendungsfall abhängig. Wichtig ist abzuwägen, ob die Quellsysteme überhaupt Streaming unterstützen. Denn auch wenn kontinuierlich Daten produziert werden, heißt dies nicht, dass sie auch kontinuierlich bereitgestellt werden.
Wenn die Implementation von Stream Processing jedoch technisch möglich ist, können die gewonnen Möglichkeiten den entscheidenden Vorteil bringen.
Mehr Informationen über Streaming im Big Data Lake und die Wettbewerbsvorteile durch die Echtzeitdatenverarbeitung in der Cloud finden Sie hier.




