Deep-Learning im Digital Business

Wenn es um die Zukunft datengetriebener Anwendungen geht, wird kaum ein Begriff aus der Data Science Welt aktuell häufiger genannt – wenn nicht sogar gehypt – als Deep-Learning. Doch was unterscheidet Deep-Learning von anderen Machine-Learning-Konzepten und wie funktioniert das „Lernen“ dieser neuronalen Netze?
Dieser Artikel zeigt auf, was man unter dem Begriff Deep-Learning versteht, wo er einzuordnen ist und welchen Nutzen Unternehmen aus Deep-Learning-Modellen ziehen können. Wann sollten solche Modelle eingesetzt werden und, vor allem, welche Anwendungen gibt es für sie im Marketing?
Was ist Deep-Learning?
Auch wenn Deep-Learning aktuell in aller Munde ist, sind doch die theoretischen und methodischen Grundlagen dieses Ansatzes schon seit den 1950ern bekannt. Seit vielen Jahren wird intensiv an der Theorie der neuronalen Netze geforscht. Allerdings waren es vor allem technische Beschränkungen, die in der Vergangenheit einen praktischen Einsatz, selbst einfacher Neuronaler Netze, verhinderten. Erst durch die Möglichkeiten des verteilten Rechnens, der Nutzung von GPUs und methodischer Erweiterungen, ist es möglich geworden, die extrem komplexen Rechenoperationen zur Schätzung neuronaler Netze (kosten-)effizient durchführen zu können. Und damit beginnt dann auch der praktische Erfolg dieser Verfahren.
Ein einfaches Neuronales Netz (Perzeptron) besteht aus einer Eingabegabeschicht (Input Layer), einer „verarbeitenden“ Schicht (Hidden Layer) sowie einer Ausgabeschicht (Output Layer). Die Elemente der Hidden Layer (Neuronen) ordnen den verschiedenen Input-Signalen ein Output-Ergebnis zu. Dabei werden die Input-Signale gewichtet und meist mittels einer nichtlinearen Aktivierungsfunktion transformiert. Kurz gesagt bezeichnet man Neuronale Netze mit mehr als einem Hidden Layer als Deep-Learning Modelle. Bei diesen bilden die Outputs der Neuronen aus der ersten Schicht den Input für die verarbeitenden Neuronen der zweiten Schicht usw.
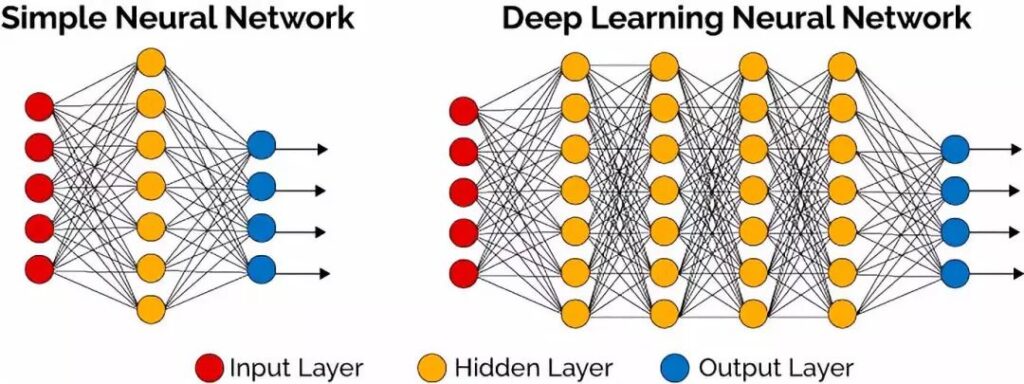
Durch die komplexe „Verschachtelung“ mehrerer, nicht-linearer Transformationen sind Deep-Learning-Modelle in der Lage, beliebig komplexe Zusammenhänge in Daten zu repräsentieren. Diese Fähigkeit ist besonders im Bereich Image Mining von großer Bedeutung, wo es unter anderem darum geht komplexe optische Strukturen aus Bilddaten zu identifizieren.
Was unterscheidet Deep-Learning von anderen Machine-Learning-Ansätzen?
Der wesentliche Unterschied von Deep-Learning-Modellen zu anderen Machine-Learning-Ansätzen besteht darin, dass Deep-Learning-Netze quasi auf den „rohen“ Eingangsdaten arbeiten und diese Schritt für Schritt (über die verschiedenen Hidden Layer) zu neuen Repräsentationen der Eingangsinformationen verdichten. Dieses als „Representation Learning“ bezeichnete Prinzip führt im Grunde eine Art „integriertes Feature Engineering“ durch. Klassische Machine-Learning-Verfahren hingegen erwarten üblicherweise manuell und anhand fachlicher bzw. statistischer Expertise aufbereitete Features.
Durch die zahlreichen Hidden Layer eines Deep-Learning-Modells verfügt dieses über eine hohe Abstraktionsfähigkeit und es ist dadurch sichergestellt, dass alle relevanten Informationen aus den Eingangsdaten tatsächlich auch zur Prognose oder Klassifikation verwendet werden können. Beim klassischen Feature Engineering Prozess kann es hingegen schon mal passieren, dass eigentlich wichtige Features doch nicht gebildet werden und dann folglich auch nicht für die eigentlich Machine-Learning Aufgabe zur Verfügung stehen.
Allerdings stehen diesen expliziten Stärken von Deep-Learning-Modellen auch Herausforderungen in der praktischen Anwendung gegenüber. Zum einen wird für eine erfolgreiche Entwicklung eines Deep-Learning-Netzwerkes eine sehr große Anzahl an Trainingsdaten benötigt und zum anderen braucht es zur Schätzung der vielen Tausend Parameter eines Deep-Learning-Netzwerks häufig spezielle Hardware und extrem große Rechenkapazitäten. Und schließlich erhält man mit einem Deep-Learning-Modell ein sehr mächtiges Werkzeug. Aber selbst für den erfahrenen Data Scientist ist es sehr schwer nachzuvollziehen, anhand welcher Art und Gewichtung der verschiedenen Input-Kriterien das Modell zu einem bestimmten Ergebnis kommt.
Praktische Anwendung von Deep-Learning-Modellen
Auch wenn die praktischen Anwendungen eher noch am Anfang stehen, haben sich doch einige Use Cases etabliert bei denen die Methode tiefer neuronaler Netze nicht mehr wegzudenken ist.
Unter anderem konnten bei der Analyse von Bild- und Videodaten große Fortschritte erzielt werden. Die Techniken, die hierbei zu Einsatz kommen, sind sogenannte Convolutional Neural Networks. Dabei werden Filter auf den Input – das Bild – angewendet, mit deren Hilfe Kanten oder Ecken in allen Farbkanälen repräsentiert bzw. gelernt werden. Im weiteren Verlauf dieser hierarchischen Struktur werden diese „gefilterten“ Ecken und Kanten zu komplexeren Geometrien aggregiert. Das eröffnet sehr vielseitige Anwendungen.
Auch der Fortschritt bei der Verarbeitung von Text- und Sprachinformation hängt signifikant mit dem verstärkten Einsatz von Deep-Learning-Technologien zusammen. Um solche Daten, die meist in einer festen sequenziellen Reihung vorliegen, zu analysieren, kommen Recurrent Neural Networks zum Einsatz. Chatbots basieren im Wesentlichen auf diesen Ansätzen.
Deep-Learning im Marketing
Wo kann Deep-Learning sinnvoll im Marketing eingesetzt werden?
Bilder bieten eine umfangreiche Informationsquelle. Wenn diese genutzt werden soll, kommt man um Deep-Learning nicht herum. Produktbilder können ausgewertet werden, um bessere Empfehlungen zu generieren: Welche Produkte passen zu einem Kunden aufgrund des Aussehens, des Stils, der Farbgebung etc. Damit lässt sich eine hohe Präzision insbesondere für Neukunden oder für neue Produkte erreichen, die bei klassischen Recommender-Verfahren zusätzliche Herausforderungen darstellen. In unserem Beitrag zu Image Based Recommendations sind wir schon auf dieses Thema eingegangen.
Ein weiterer Anwendungsfall ist die Auswertung von Customer Journeys. Die Komplexität durch die vielen möglichen Kontaktpunkte und die Notwendigkeit, den zeitlichen Verlauf zu berücksichtigen, machen die klassische Ableitung von Features bzw. beschreibenden Variablen sehr aufwändig. Mittels Deep-Learning können die vielen Dimensionen flexibel reduziert und nutzbar gemacht werden.
Abwägungen
Der Einsatz von Deep-Learning muss immer abgewogen werden. Dem genannten Nutzen stehen auch Kosten gegenüber. So braucht man für große neuronale Netzwerke viele Daten, oft spezielle Hardware und teilweise extreme Rechen-Ressourcen für die Erstellung der Modelle.
Weiterhin kann nicht mehr so einfach nachvollzogen werden, welche Faktoren im Modell in welchem Ausmaß wirken. Wenn die Daten z.B. menschliches Verhalten abbilden – wie im Falle von Kaufentscheidungen – dann können sich die Gründe für Ergebnisse mit der Zeit verändern, wie sich auch menschliches Verhalten ändern kann.
Bei dem Erkennen von Bildern sieht das anders aus. Den Aufwand zu validieren, warum ein Bild als Katze klassifiziert wird, kann man betreiben, da sich die Gründe – Was macht eine Katze zu einer Katze? – mit der Zeit nicht ändern werden. Oder bei der Erkennung von Texten: Was eine handschriftliche zwei zu einer zwei macht, bleibt mit der Zeit konstant. Man benötigt aber sehr feine Unterscheidungsmöglichkeiten des Modells, um handschriftliche Zahlen zu identifizieren und gerade dafür ist Deep-Learning äußerst nützlich.
© Titelbild: sdecoret | www.stock.adobe.com

