Big Data Lake
Eine steigende Nachfrage bei Unternehmen treibt das Konzept Data Lake mittlerweile stark voran. Dabei ergibt sich dieser Bedarf an „Datenseen“ primär aus den gewachsenen Anforderungen an das Datenmanagement. Unternehmen stehen hier vor der Herausforderung mit exponentiell steigenden Datenmengen zu arbeiten. Zudem bedeutet ein intelligenter Umgang mit Big Data auch ein wirtschaftliches Wachstum. So ergeben sich vermehrt Möglichkeiten der Analyse und des maschinellen Lernens. Unternehmen können dies gezielt nutzen, um einen Wettbewerbsvorteil zu erzielen. Hinzu kommen gesetzliche Anforderungen an das Datenmanagement, die durch das neue europäische Datenschutzgesetz (DSGVO) in Kraft getreten sind.
Was bedeutet Data Lake?
Ein Data Lake – auf Deutsch Datensee – bezeichnet eine zentralisierte Sammlung an Daten. Datenströme, die in einen Datensee fließen, müssen dabei nicht vorab strukturiert werden.
Die Idee des Data Lakes besteht darin, alle Unternehmensdaten in ihrer ursprünglichen Form an einem Ort abzulegen. Personen und automatisierte Software-Systeme entnehmen dem Data Lake anschließend Daten, um diese je nach Bedarf aufzubereiten. Die Anwendungsbeispiele sind vielfältig: Von Machine Learning, Big Data Processing und Realtime Data Streaming bis zu komplexen Visualisierungen können Sie alles auf einem Data Lake aufsetzen.
Im Zusammenhang mit Data Lake wird ebenfalls häufig der Begriff Data Swamp verwendet. Bildlich kann man sich diesen als einen umgekippten See vorstellen. Dieser Datensumpf kann nicht für seinen vorgesehenen Zweck benutzt werden und liefert aufgrund seiner Struktur wenig Mehrwert für das Unternehmen.
Die nachfolgende Grafik veranschaulicht die Datensammlung anhand eines Event-Streams und die Zusammenführung im Data Lake.
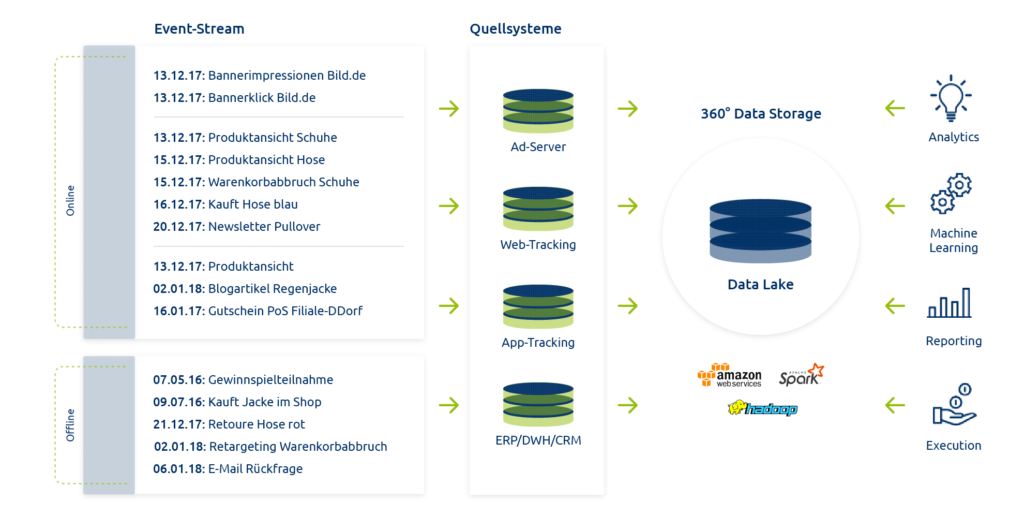
Data Lake bedeutet eine zentralisierte Sammlung an externen und internen Daten auf die Mechanismen zum Machine Learning, Big Data Processing und zur Visualisierung zugreifen.
Warum Data Lake?
Der Begriff Data Lake liefert eine bildliche Vorstellung des zugrundeliegenden Konzepts. Alle Daten eines Unternehmens fließen als Ströme in den Datensee. Aus dem See können im Anschluss verschiedene Proben wie Wassergläser entnommen oder betrachtet werden. Data Lake ist ein Anglizismus für das deutsche Wort Datensee – einem gigantischen Speicherort, der von verschiedenen Datenströmen gespeist wird.
“If you think of a data mart as a store of bottled water – cleansed and packaged and structured for easy consumption – the data lake is a large body of water in a more natural state. The contents of the data lake stream in from a source to fill the lake, and various users of the lake can come to examine, dive in, or take samples.”
James Dixon, CTO von Pentaho, schuf den Begriff Data Lake als eine Neuerung zu dem Konzept Data Marts.
Was ist ein Data Lake?
Das Konzept löst Probleme, die bei Data Marts eventuell aufkommen können. In einer Metapher vergleicht Dixon ein Data Mart mit einer Flasche Wasser. Die Daten liegen aggregiert vor, sodass Informationen auf einem niedrigeren Level verloren gehen. Es können nur bestimmte Attribute des Wassers untersucht und somit nur vordefinierte Fragen beantwortet werden.
Bei einem Datensee existieren diese Probleme nicht, da alle Daten in ihrer ursprünglichen Form an einem zentralen Ort versammelt werden.
Ein Data Lake beinhaltet strukturierte Daten von relationalen Datenbanken, teilweise strukturierte Daten (z.B. CSV- ,XML- , JSON- oder Log-Dateien), unstrukturierte Daten (z.B. E-Mails und Dokumente) und binäre Daten (z.B. Bild-, Ton- und Videodateien). Die Daten können sowohl aus dem eigenem Unternehmen als auch aus externen Quellen entstammen. Externe Quellen sind beispielsweise Markterhebungen oder Social-Media-Netzwerke.
Ein Data Lake vereint strukturierte, teilweise strukturierte und nicht strukturierte Daten an einem Ort. Diese Daten können anschließend verarbeitet und analysiert werden.
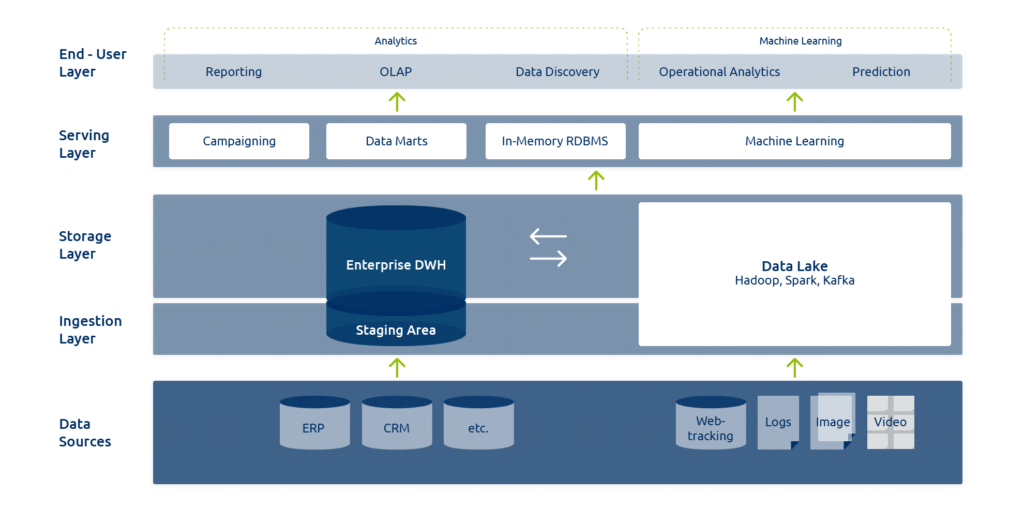
Wie in der Grafik ersichtlich wird, beziehen verschiedene Systeme aus dem Datensee Daten, um diese zu analysieren und zu verarbeiten
Data Lake vs. Data Warehouse
Das Konzept Data Lake klingt im ersten Moment ähnlich wie das des Data Warehouse. Ein Data Warehouse bezeichnet ebenfalls einen zentralen Speicher an Daten, auf dem Analyse- und Reporting-Mechanismen aufgesetzt werden können.
Trotzdem unterscheiden sich beide Konzepte erheblich: Während ein Data Warehouse mit sehr strukturierten Daten gespeist wird, kann ein Datensee mit den unterschiedlichsten Datenquellen geflutet werden, ohne dabei unübersichtlich zu werden. Das liegt zum einen an der Realtime-Verarbeitung der Daten, zum anderen an der extremen Dynamik eines Data Lakes.
In der folgenden Grafik werden die bislang gewonnenen Erkenntnisse zu Data Lake und Data Warehouse noch einmal anschaulich dargestellt:
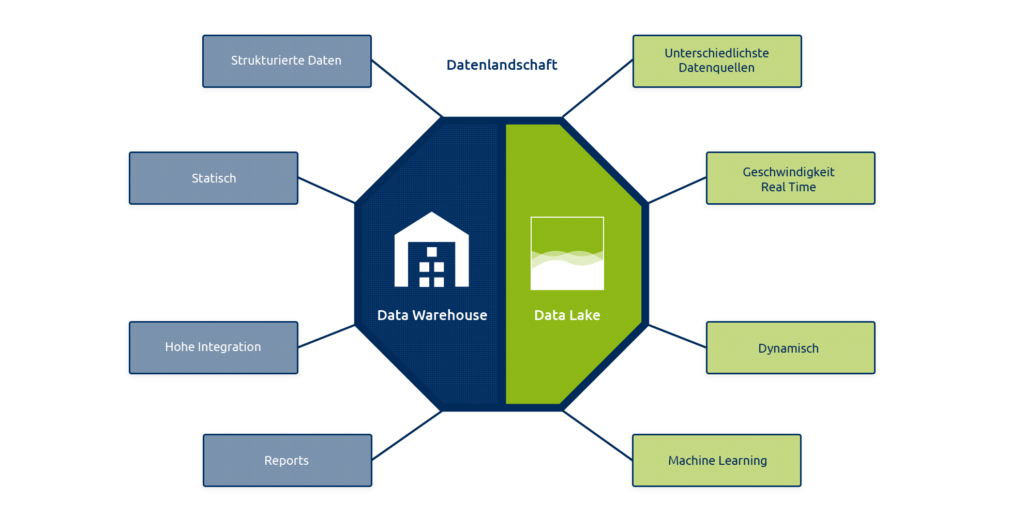
Der Unterschied zwischen den beiden Konzepten liegt also primär in der Speicherung der Daten. Und obwohl derzeit noch primär das Data Warehouse genutzt wird, um die wichtigste Businesslogik abzubilden, ist der Data Lake auf dem Vormarsch. Es ist zu vermuten, dass künftig immer mehr Datenseen parallel zu Daten- „Warenhäusern“ existieren. Der Trend zum hybriden Modell mit einer Koexistenz von Data Lake und Data Warehouse wird sich zunehmend verschärfen. Durch die gewonnene Fülle an Daten bietet ein Data Lake gute Voraussetzungen für Advanced Analytics – also fortgeschrittene und komplexe Analysemethoden. Die folgende Tabelle zeigt die detaillierten Unterschiede zwischen Konzepten auf auf:
| Eigenschaften | Data Warehouse | Data Lake |
|---|---|---|
| Daten | Strukturierte Daten aus operativen Datenbanken, Systemen und Anwendungen | Strukturierte, teilweise strukturiert und unstrukturierte Daten aus operativen Datenbanken, Systemen, Anwendungen, IoT-Geräten, Websites, mobilen Apps, sozialen Medien und externen Informationsanbietern |
| Datenschema | Wird vorab festgelegt und die Daten strukturiert eingeordnet | Wird erst zu dem Zeitpunkt der Analyse erstellt |
| Verhältnis von Preis und Performance | Schnelle Abfragen werden durch hochpreisigen Speicher gewährleistet | Abfragen werden schneller über günstigen Speicher |
| Qualität der Daten | Aufbereitete Daten | Alle Daten, egal ob aufbereitet oder nicht |
| Benutzer | Business-Analysten | Datenwissenschaftler, Datenentwickler und Business-Analysten |
| Analysen | Batch Reporting, Business Intelligence, Visualisierungen | Machine Learning, Vorausschauende Analysen, Datenerkennung und Profilerstellung |
Wieso sollten Unternehmen einen Data Lake einsetzen?
Aus einer Erhebung von Statista 2017 geht hervor, dass die Datenmenge in Zettabyte um das zehnfache im Zeitraum von 2016 bis 2025 steigen wird und von jährlich 16,1 auf unglaubliche 163 Zettabyte wächst. Ein Zettabyte entspricht dabei der Menge von 1.000.000.000 Terabyte.
Es existieren bereits einige Studien – beispielsweise vom US-amerikanischen Technologieunternehmen Aberdeen Group – die aufzeigen, dass Organisationen, die einen Mehrwert aus ihren Geschäftsdaten ziehen können, vor ihren Mitbewerbern liegen.
Unternehmen sollten in der Lage sein, Zusammenhänge zwischen internen Firmendaten und externen Daten zu erkennen und daraus Schlüsse auf ihr Unternehmen zu projizieren. Vorreiter in diesem Bereich können durch die gewonnen Informationen potenzielle Kunden identifizieren und gewinnen. Schlussendlich lassen sich so fundierte Entscheidungen für die künftige Unternehmensausrichtung treffen.
Ein Data Lake ermöglicht, diese Zusammenhänge aufgrund des gemeinsamen Aufbewahrungsorts der Daten zu ermitteln.
Darüber hinaus ist es möglich, auf Daten in einem Datensee flexibel und schnell zuzugreifen. Unternehmen mit einer agilen Datenstrategie finden daher in diesem Konzept ihre Lösung.
Ein Data Lake bietet Möglichkeiten für einen wirtschaftlichen Umgang mit Unternehmens- und externen Daten.
Vorteile Retail Data Lake
Ein Data Lake schafft eine 360°-Sicht auf die Kunden eines Unternehmens. Dabei sind alle Datenquellen integriert und verbunden, so beispielsweise E-Commerce, ERP, Transaktionen, Kundensupport und Supply-Chain-Informationen. Durch den Einsatz von Big Data-Technologie und Cloud-Architektur ergeben sich somit immense Vorteile:
- Keine Grenzen in Bezug auf Speicherplatz und Rechenleistung
- Data Lake als Plattform für Machine Learning und Reporting
- Dedizierte Hardware für Machine Learning und Deep Learning ermöglicht neue Ansätze
- Echtzeitverarbeitung (Data Streaming) von Datenquellen schafft Wettbewerbsvorteil und kurze Reaktionszeiten
- Die zentrale Sicht auf große Datenmengen verbessert Marketingmaßnahmen, Loyalitätsprogrammen, Vertriebsprozesse, Service und Produktentwicklung.
Technologie-Anbieter
Anbieter von Data Lake Services gibt es mittlerweile einige am Markt. Dazu zählen unter anderem Amazon, Microsoft, Hortonworks, Google, Oracle, Cloudera, Zaloni und Teradata.
Die drei größten Anbieter von Data Lake as a Service (DLaaS) sind Amazon, Microsoft und Google. Diese „Big Player“ des Online-Zeitalters verlassen sich auf den Speicherservice ihrer jeweiligen Cloud: S3 bei Amazon, Azure Storage bei Microsoft und Cloud Storage bei Google. Alle drei nehmen dafür Apache Hadoop als Grundlage. Apache Hadoop ist eine Sammlung von Opensource Software-Komponenten, welche die Verarbeitung und Speicherung von Big Data regeln.
In der folgenden Tabelle sind die wichtigsten Eigenschaften der drei Anbieter gegenübergestellt.
| Eigenschaft | Amazon Web Services | Google Cloud Platform | Microsoft Azure |
|---|---|---|---|
| Big Data Technologie | Google Elastic MapReduce mit Apache Hadoop, Apache Spark, Habse, Flink, Presto, KafkaApache Spark von Databricks in managed modeStorage | Google DataProc mit Apache Hadoop und Spark | SparkAzure HDInsight mit Apache Hadoop, Spark, Server R, HBase, Storm und KafkaApache Spark von Databricks in managed modeStorage |
| Storage-Technologie | Amazon S3, Amazon GlacierGoogle, Amazon RedShift, AWS Glue, AWS Batch | GoogleBigQuery, Google DataFlow | Azure Storage, Azure Data LakeAzure SQL Data Warehouse, Azure Data Factory, Azure Batch |
| Serverless Abfragen | Amazon Athena | – | Azure Data Lake Anaytics |
| Echtzeitverarbeitung | Amazon Kinesis, Apache Kafka | Google DataFlow, Google PubSub | Azure Event Hub, Azure Stream Analytics |
| Business Intelligence und Data Mining | Amazon QuickSight | Google Data Studio | PowerBI |
| Datenmigration | AWS Database Migration Service, AWS Snowball | Cloud Datarep | Azure Database Migration Service, Azure Data Box |
| Datenkatalog | AWS Glue Data Catalog | – | Azure Data Catalog |
| Mechanismus zur Identifikation personenbezogener Daten | Amazon Macie | Kein Service, aber es wird eine API angeboten | Azure Data Catalog |
| Physischer Standort der Systeme in Europa | – | – | Ja |
Amazon gilt mit seinem bereits 2009 angebotenen Datenrahmenwerk als Vorreiter der DLaaS-Bewegung, während Microsoft und Google erst ca. drei Jahre später eingestiegen sind. Aufgrund dieses Vorsprungs wird Amazon als technologisch reifer angesehen – gerade in Bezug auf die Speicherung und Verarbeitung von Big Data.
Microsoft und Google hingegen gelten als stärker aufgestellt im Bereich des maschinellen Lernens.
Ein aktuelles Alleinstellungsmerkmal der DLaaS-Lösung von Microsoft ist, dass ein physischer Standort in Europa gewährleistet werden kann. Im Hinblick auf den Datenschutz von Unternehmens- und personenbezogener Daten kann dieser Punkt ausschlaggebend für die Wahl des DLaaS-Anbieters sein.
Data Lake und Datenschutz
Seit Mai 2018 muss die europäische Datenschutz-Grundverordnung (DSGVO) zusammen mit einer Erneuerung des Bundesdatenschutzgesetzes angewandt werden.
Bei der Implementierung eines Data Lake können die Anforderungen der DSGVO einfach umgesetzt werden. Die Anlage logisch separierter Datenbereiche ermöglicht die klare Trennung zwischen personenbezogenen Daten, die im Klartext vorliegen müssen, und anonymisierten Daten. Zu den Klardaten, muss eine Verknüpfung zu dem Einverständnis des Kunden für die Aufbewahrung eingerichtet werden.
Ebenfalls analysiert und definiert werden muss der Zweckbezug von Daten, die im Klartext vorliegen. Operative Anwendungen müssen meist mit Klardaten arbeiten – das ist durch den Zweckbezug innerhalb bestimmter zeitlicher Rahmen unabdingbar.
Die Experten der DYMATRIX unterstützen Sie bei einer datenschutzkonformen Umsetzung Ihres Big Data Projekts.
Wichtige Punkte bei dem Aufbau eines Data Lake sind demnach logisch voneinander getrennte Bereiche und Prozesse zur Pseudonymisierung sowie Anonymisierung.
Data Lake folgt Data Mart und Data Warehouse
Egal, ob ein Unternehmen seinen Umgang mit Daten aufgrund von gesetzlichen Vorschriften, wirtschaftlichen Anforderungen überdenken muss oder die wirtschaftlichen Vorteile eines Data Lakes nutzen möchte: In allen Fällen ist das Thema Datenmanagement für Unternehmen von hoher Priorität. Die Zukunft der Wirtschaftlichkeit eines Unternehmens hängt stark von dessen Umgang mit internen sowie externen Daten zusammen. Können Datenzusammenhänge gezielt erkannt werden, lassen sich fundierte Entscheidungen für die Unternehmensziele treffen. Ein Data Lake vereinfacht im Vergleich zu einem Data Mart oder Data Warehouse diesen Prozess und bietet eine Plattform, um mit den Innovationen im Bereich des maschinellen Lernens mitzuhalten.
Mit DYMATRIX die Herausforderungen von Big Data angehen
Aufgrund der immer größeren Ansammlung von Big Data, ist das Konzept Data Lake immer wichtiger. Die dynamische Integration von Datenquellen durch die Big-Data-Technologie sorgt für schnellere Datenbeschaffung und kürzere Projektzeiten. Auch die Möglichkeiten in Bezug auf Machine Learning und Realtime Data Streaming ermöglichen neue Use Cases und schaffen so einen echten Mehrwert für unsere Kunden.
